Networking for AI Datacenters
The Complete Learning Guide to High-Performance AI Infrastructure
Learning Path
1. Fundamentals
Why AI needs special networking
2. Technologies
InfiniBand, Ethernet, RoCE
3. Architectures
Topologies and design patterns
4. Real World
Case studies and implementations
AI Network Requirements
Key Communication Patterns
AI training relies on specific communication patterns:
All-Reduce Operations
Purpose: Synchronize model gradients across all GPUs
Network Impact: Requires full bisection bandwidth during gradient synchronization
Example: GPT-3 175B parameters = 1.4TB per all-reduce operation
Traffic Characteristics
- 99.9% East-West Traffic
- 64KB - 1MB Message Size Range
- Elephant Flows - Large, sustained transfers
- Synchronized Communication Pattern
Latency Requirements
Target: Less than 1.5μs end-to-end latency
- NIC Processing: 0.3-0.5μs
- Switch Fabric: 0.1-0.2μs
- Protocol Overhead: 0.1-0.3μs
Core Technologies
InfiniBand
What it is: High-performance interconnect designed for HPC and AI workloads
Key Features:
- Ultra-low latency: 600ns end-to-end
- High bandwidth: Up to 400 Gbps per link
- RDMA support: Direct memory access without CPU involvement
- Minimal CPU overhead: Less than 1% CPU usage
Transport Types:
- RC (Reliable Connected): Best for RDMA operations
- UD (Unreliable Datagram): Used for management traffic
RoCE (RDMA over Converged Ethernet)
What it is: Brings InfiniBand performance to standard Ethernet infrastructure
Versions:
- RoCEv1: Layer 2 only, same broadcast domain
- RoCEv2: Layer 3 routable, production standard
Key Technologies:
- DCQCN: Congestion control algorithm
- PFC: Priority Flow Control for lossless operation
- ECN: Explicit Congestion Notification
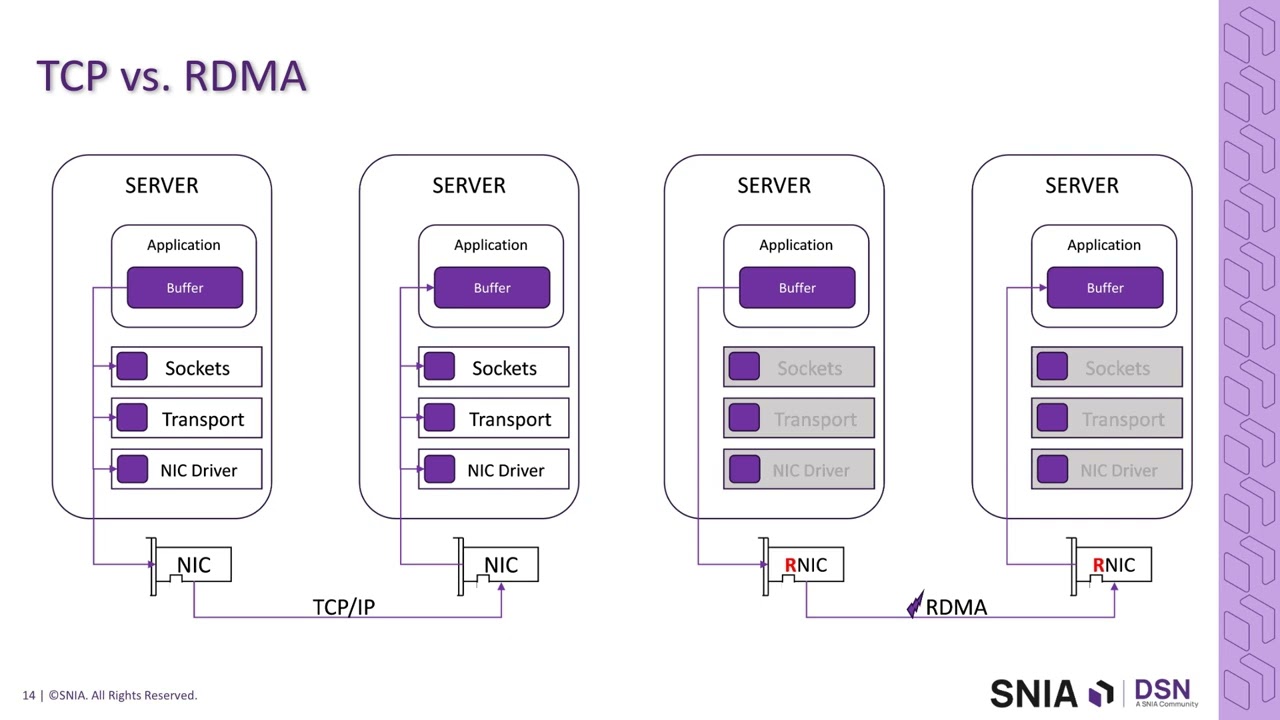
How RDMA Works
- Memory Registration: Applications register memory regions
- Direct Access: Remote applications can read/write directly
- Kernel Bypass: No CPU involvement in data path
- Zero Copy: Data moves directly between application memory
Performance Benefits:
- 95% CPU reduction - Frees CPU for computation
- 10x bandwidth improvement - Higher throughput
- 5x latency reduction - Faster communication
Emerging Technologies
Ultra Ethernet Consortium
Industry initiative to enhance Ethernet for AI workloads:
- Enhanced congestion control algorithms
- Improved multicast and telemetry support
- Better job scheduling integration
NVIDIA SHARP
In-network computing for AI collective operations:
- All-reduce operations in network switches
- Reduces network traffic significantly
- Up to 2x acceleration for large models
Network Architectures
Leaf-Spine (Clos Fabric)
What it is: The most common architecture for AI data centers
Key Characteristics:
- Non-blocking: Every server can communicate at full speed
- Scalable: Add more leaf switches to grow capacity
- Low oversubscription: 1:1 to 3:1 ratios typical
- ECMP load balancing: Multiple paths between endpoints
Multi-Rail Design:
- Rail 0: Compute traffic (RoCE/InfiniBand)
- Rail 1: Storage traffic (NVMe-oF)
- Rail 2: Management traffic
DragonFly+ Topology
What it is: Advanced topology for extremely large-scale AI clusters
Key Features:
- Hierarchical design: Groups of routers connected globally
- Adaptive routing: Routes adapt based on congestion
- High scalability: Supports 100,000+ endpoints
- Fault tolerance: Multiple paths between any two points
Scaling Examples
Pod-Based Architecture (Meta)
- Scale: 2,000-4,000 GPUs per pod
- Within pod: 400G InfiniBand
- Between pods: Ethernet spine
3D Torus (Google TPU)
- Scale: 100,000+ accelerators
- Topology: Custom 3D mesh
- Bandwidth: 2.4Tbps per chip
AI Traffic Patterns
All-Reduce (Model Synchronization)
- Pattern: Every GPU communicates with every other GPU
- Requirement: Full bisection bandwidth
- Algorithms: Ring, tree, or hierarchical approaches
All-Gather (Data Distribution)
- Pattern: Collect data from all nodes
- Use case: Embedding updates, parameter sharing
- Bottleneck: Memory bandwidth
Point-to-Point (Data Loading)
- Pattern: Storage to compute (north-south)
- Characteristics: Large sequential transfers
- Solution: Separate storage network or QoS
Real-World Case Studies
OpenAI GPT Infrastructure
- Scale: 25,000+ NVIDIA V100/A100 GPUs
- Network: InfiniBand HDR (200Gbps)
- Platform: Microsoft Azure
- Innovation: Custom optimization for transformer models
Meta AI Research SuperCluster (RSC)
- Scale: 16,000 NVIDIA A100 GPUs
- Network: NVIDIA Quantum InfiniBand (400Gbps)
- Storage: 175PB Pure Storage FlashArray
- Design: Non-blocking fat-tree, 1:1 oversubscription
Meta Announcement | Technical Deep Dive
NVIDIA DGX SuperPOD
- Scale: 160 H100 GPUs per pod
- Network: Quantum-2 InfiniBand (400Gbps)
- Performance: 8 exaflops FP8, sub-μs latency
- Efficiency: >90% scaling up to 32,000 GPUs
Architecture Guide | Technical Overview
Google TPU Pod
- Scale: 100,000+ accelerators
- Topology: Custom 3D torus
- Bandwidth: 2.4 Tbps per chip
- Innovation: Hardware all-reduce implementation
Implementation Guide
Planning Your AI Network
Key Questions:
- What's your target model size?
- Training vs. inference workload?
- Budget constraints?
- Growth plans?
Technology Selection:
Choose InfiniBand if:
- Ultra-low latency required (<1μs)
- Budget allows premium cost
- Pure HPC/AI workloads
- NVIDIA GPU ecosystem
Choose RoCE if:
- Cost optimization priority
- Multi-vendor preference
- Existing Ethernet expertise
- Mixed datacenter workloads
Design Principles:
- Low oversubscription: 1:1 or 2:1 ratios (vs. 20:1 enterprise)
- Fault tolerance: Single switch failure shouldn't stop jobs
- Cable management: Plan early - AI clusters are cable-dense
Configuration Checklist:
RoCE Setup:
- Enable PFC on appropriate traffic classes
- Configure DCQCN congestion control
- Set buffer sizes (20MB+ recommended)
- Enable ECN marking
System Optimization:
- NUMA topology awareness
- CPU affinity for RDMA interrupts
- Jumbo frames (9000+ bytes MTU)
- Network buffer tuning
Monitoring & Troubleshooting
Key Monitoring Tools
InfiniBand:
ibstat- Check adapter statusperfquery -a- Performance countersibnetdiscover- Fabric discovery
RoCE/Ethernet:
ethtool -S eth0- Interface statisticsdcbtool gc eth0 pfc- PFC status- Monitor PFC pause frames and ECN marks
NCCL Performance:
nccl-tests/build/all_reduce_perf- Benchmark collectives- Set
NCCL_DEBUG=INFOfor detailed logging - Monitor algorithm bandwidth (algbw) and bus bandwidth (busbw)
Common Issues & Solutions
RDMA Transport Timeouts:
- Symptoms: Connection failures, QP errors
- Check: Cable integrity, switch buffer config
- Fix: Increase timeout values, replace cables
PFC Deadlocks:
- Symptoms: Sustained pause storms, traffic stoppage
- Check: PFC counters with
ethtool -S - Fix: Enable PFC watchdog, tune buffer thresholds
Poor All-Reduce Performance:
- Symptoms: Low bandwidth utilization
- Check: GPU-NIC affinity with
nvidia-smi topo -m - Fix: Tune NCCL algorithms, check network balance
Packet Corruption:
- Symptoms: CRC errors, symbol errors
- Check: Physical layer stats with
ibstat - Fix: Replace cables, check FEC settings, update firmware
Performance Targets
- Latency: InfiniBand <1μs, RoCE <2μs
- Bandwidth utilization: >90% for AI workloads
- Packet loss: 0% (lossless with PFC)
- All-reduce efficiency: >80% of theoretical
Expert Video Resources
Learn from industry experts with these carefully curated video resources:

AI Data Center Networks - Fundamentals
Comprehensive overview of networking challenges and solutions in AI data centers, perfect for beginners understanding the fundamental requirements.

Inside xAI Colossus: World's Largest AI Supercluster
Exclusive look inside xAI's massive 100,000-GPU Colossus supercluster networking architecture, showcasing real-world implementation at unprecedented scale.
Everything You Wanted to Know About RDMA
Comprehensive deep-dive into Remote Direct Memory Access technology, essential for understanding modern AI networking performance.

Scaling RoCE Networks for AI Training
Expert insights into scaling RoCE networks for AI training workloads, covering practical implementation challenges and solutions.

RDMA Programming: NVIDIA's Guide
NVIDIA's comprehensive guide to high-performance RDMA programming, covering practical implementation techniques for AI applications.

SIGCOMM'24: RDMA over Ethernet for AI Training
Academic presentation from SIGCOMM covering the latest research in RDMA over Ethernet implementations for distributed AI training systems.
Additional Resources
Essential Documentation
- NVIDIA Networking Documentation - InfiniBand, Ethernet, and software stack
- Ultra Ethernet Consortium - Industry specifications for AI networking
- OpenCompute Project - Open source hardware designs for datacenter networking
Tools and Software
- NCCL - GPU-aware collective communications library
- OpenMPI - High-performance message passing with RDMA support
- RDMA Performance Testing Suite - Benchmarking tools
- NVIDIA NetQ - Network operations and monitoring
Training and Courses
- NVIDIA Deep Learning Institute - Professional AI infrastructure training
- Broadcom University - Enterprise datacenter networking training
- Linux Foundation Training - Modern networking technologies
Quick Reference
Essential Commands
ibstat- Check InfiniBand adapter statusibv_devinfo- Display RDMA device informationib_write_bw- Measure RDMA write bandwidthethtool -S eth0- Ethernet interface statisticsmlnx_qos -i eth0- Check PFC and QoS status
Performance Targets
- Latency: InfiniBand <1μs, RoCE <2μs
- Bandwidth Utilization: >90% for AI workloads
- Packet Loss: 0% (lossless with PFC)
- All-Reduce Efficiency: >80% of theoretical